
AI Going Into 2026 (Part 1)
A deep analysis of where LLMs are today and what to look for in 2026...

AI Going Into 2026: The Landscape Has Fractured
A year ago, the AI narrative was simple: OpenAI led, everyone else chased. GPT-4 was the benchmark. Scale was the strategy. Sequoia called it: five “finalists” had reached GPT-4 parity, and the race was about who could train bigger, faster.
That story is over.
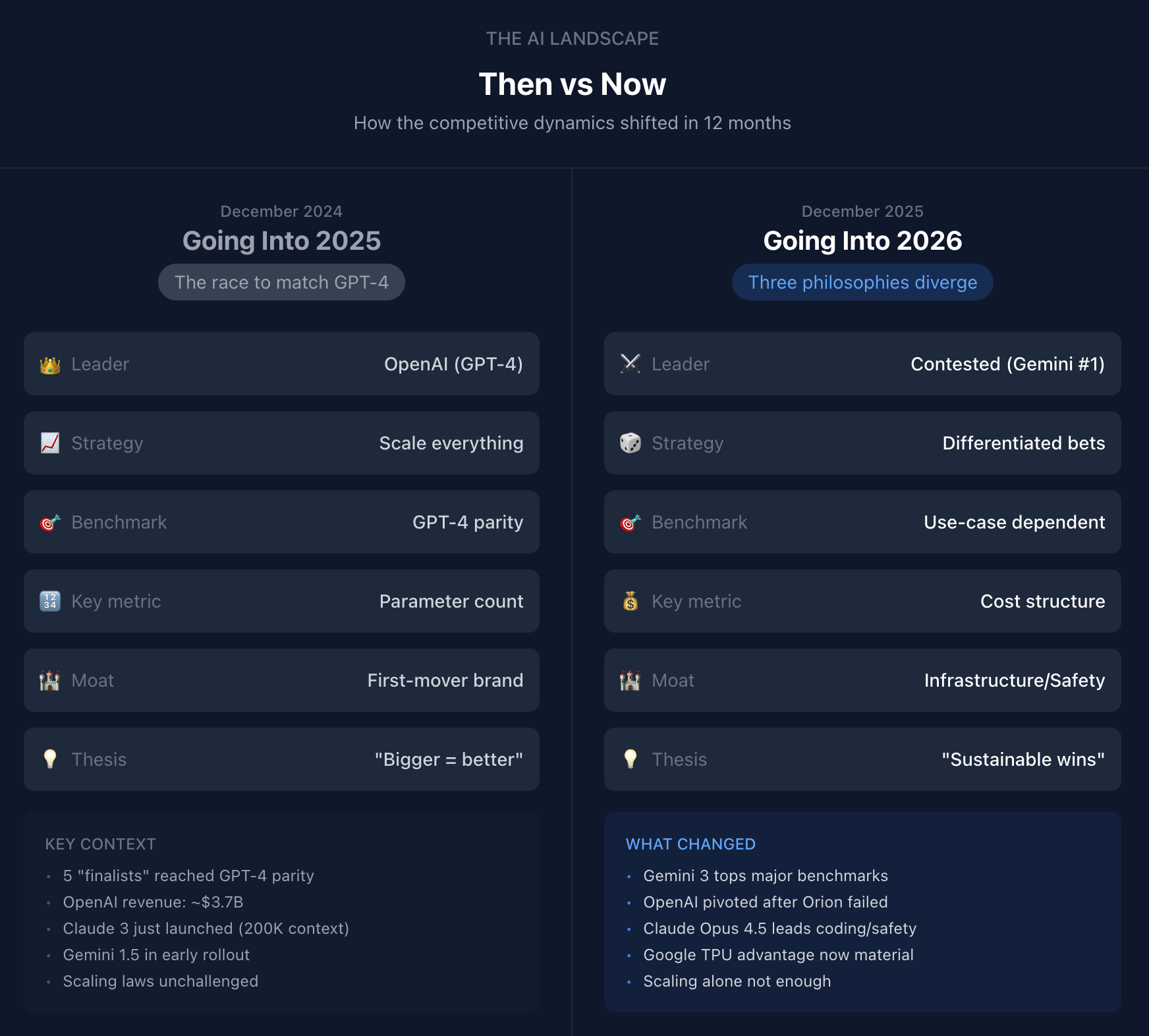
Going into 2025, the question was: Who can match GPT-4? The answer quickly became “almost everyone.” Google, Anthropic, Meta, xAI all crossed the threshold. OpenAI had the brand, the revenue ($3.7B), and the momentum. The scaling hypothesis was unchallenged. Bigger models meant better models, and the only constraint was compute.
Going into 2026, the question is different: Which philosophy of intelligence wins? The leaderboard has flipped. Google’s Gemini 3 now holds the #1 spot. OpenAI’s massive “Orion” project failed to deliver, forcing a strategic pivot. Anthropic has quietly become the enterprise standard for reliability. And most importantly, the economics have diverged: Google doesn’t pay Nvidia, OpenAI can’t afford not to, and Anthropic is hedging across cloud providers.
The fracturing isn’t temporary. These companies have made fundamentally different bets: different choices about infrastructure, about what intelligence is, about where value accrues. Those bets are now locked in by billions in sunk costs and years of specialized research.
For investors, this creates both clarity and complexity. The “picks and shovels” thesis that dominated 2023-2024 (long Nvidia, short everyone else) is fragmenting. Google doesn’t need Nvidia. OpenAI can’t survive without massive compute investment, and is currently lagging behind.
The AI value chain is no longer a single stack, it’s three parallel ecosystems with different economics, different customers, and different failure modes.
This report breaks down what happened, why it matters, and what to watch as these three minds compete for the future of intelligence.
The Post-Training Revolution: A Technical Primer
To understand why the AI landscape fractured, you need to understand the shift from pre-training to post-training as the primary lever for capability gains.
The Traditional Recipe (2018-2024):
For years, building an AI model followed a simple two-step process:
Pre-training (99% of compute): Feed the model massive amounts of internet text and train it to predict the next word. This is where the model learns facts, language patterns, and reasoning capabilities. The “P” in GPT stands for “pre-trained.”
Post-training (1% of compute): Apply a thin layer of fine-tuning to make the model helpful and safe. This included Supervised Fine-Tuning (SFT) on curated examples and Reinforcement Learning from Human Feedback (RLHF) to align outputs with human preferences.
The assumption was that capability came from pre-training. Post-training was just a “veneer,” polishing the surface without changing the underlying intelligence.
What Broke:
By late 2024, this recipe hit diminishing returns:
Scaling laws plateaued: Doubling compute no longer doubled capability. Orion’s failed training runs in late 2024 (more below) proved that throwing more data and parameters at pre-training wasn’t producing proportional gains.
Alignment tax: Heavy RLHF was making models dumber. Safety filters were pruning away complex but harmless reasoning paths, visibly reducing performance on hard problems.
Data exhaustion: The internet has a finite amount of high-quality text. Models were increasingly training on synthetic data or repeated passes over the same corpus.
The Post-Training Pivot:
The breakthrough insight: post-training could be the main source of capability gains, not just alignment. Several techniques emerged:

The key innovation in OpenAI’s O-series was Process Reward Models. Instead of training a model to produce good final answers (which encourages hiding bad reasoning), PRMs evaluate each step of the chain of thought. If step 3 of a 10-step reasoning chain is flawed, the model learns to fix step 3, not just to make the final answer look correct.
Combined with inference-time compute (letting the model generate and evaluate multiple reasoning paths before responding), this creates a system that can “think harder” about problems without requiring a larger base model.
All the major model providers now use a mix of pre and post training techniques, but the decline of brute force scaling has led each to bring a different approach.
The Three Minds of AI
The artificial intelligence landscape has fractured into three distinct competitive strategies, each reflecting fundamentally different bets about infrastructure, economics, and what intelligence actually is. For investors evaluating the AI space, understanding these divergent approaches is essential. They determine not just model capabilities, but cost structures, competitive moats, and long-term sustainability.

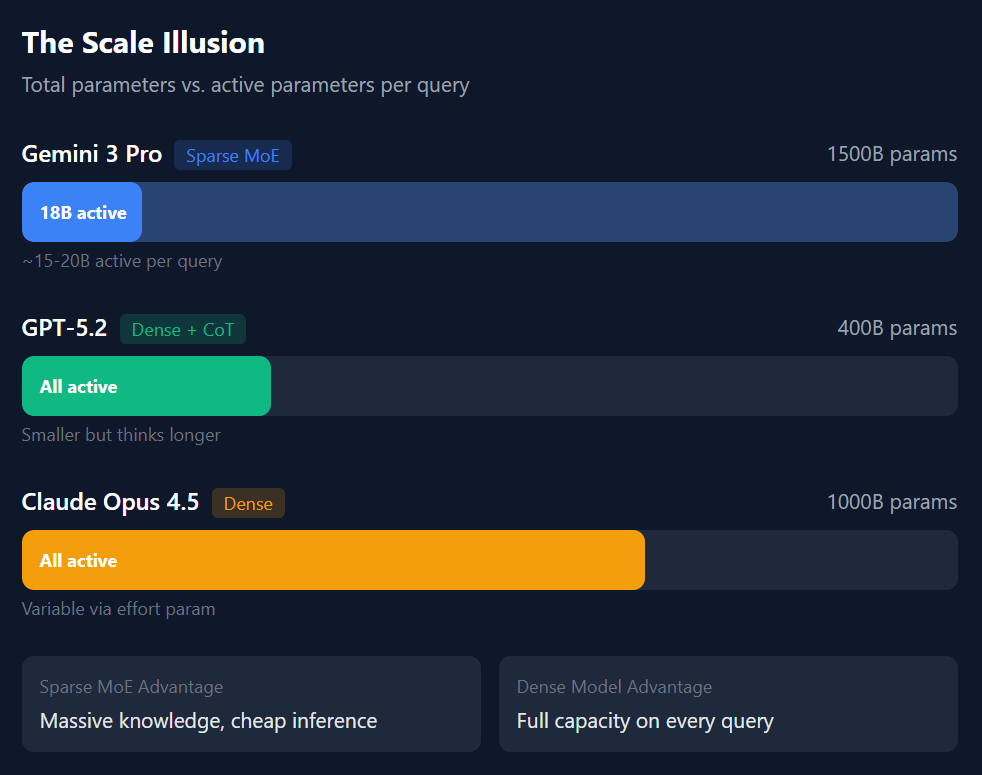
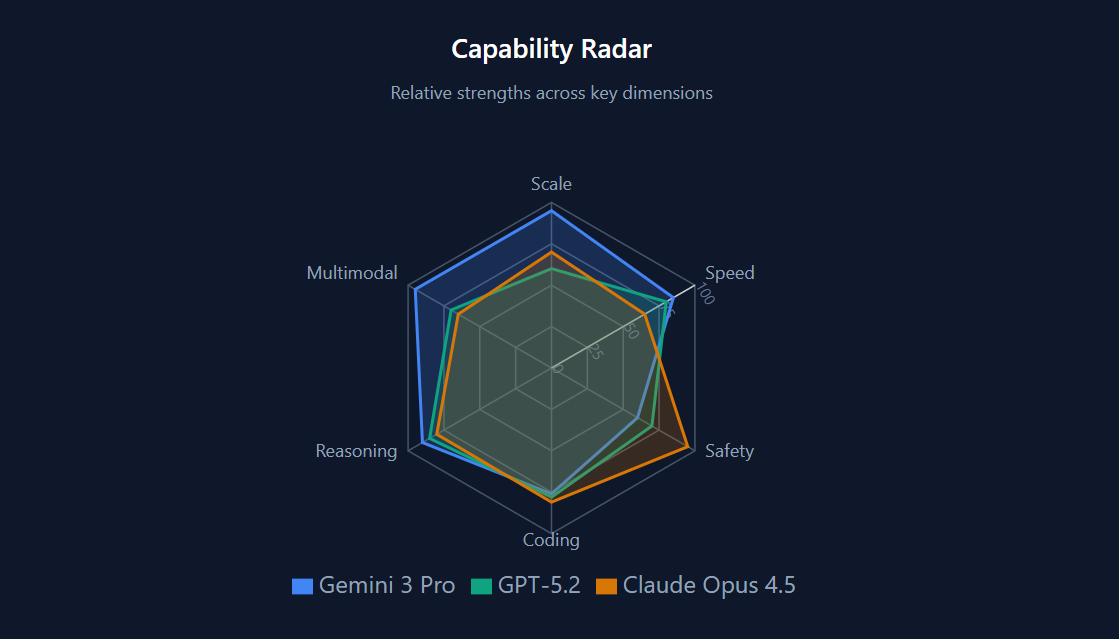
Google’s Gemini 3 represents the triumph of vertical integration. A decade of custom TPU development and pioneering research in sparse architectures has enabled Google to deploy what is likely the largest model in existence, over a trillion parameters, while maintaining competitive pricing. Gemini 3 is more than brute force, it reflects a beautiful and elegant efficiency at scale.
OpenAI’s GPT-5 represents a strategic pivot forced by economic reality. After the “Orion” project hit diminishing returns, with massive training runs that failed to deliver proportional improvements, OpenAI shifted to its new “Garlic” models, an architecture that achieves frontier performance with smaller model sizes and smarter reasoning. This is a bet on inference-time compute over training-time scale, but it’s constrained by OpenAI’s dependence on expensive Nvidia hardware until Stargate comes online.
Anthropic’s Claude Opus 4.5 represents a mixture of the two approaches. Opus 4.5 is a large model, and it combines the “wisdom” of a large training set with aggressive post-training. Rather than competing on raw scale or reasoning tricks, Anthropic has optimized for predictability, safety, and enterprise adoption—betting that as AI agents become more autonomous, the safest model wins the contracts that matter.
Part I: Why Each Lab Chose Its Path
Google: The TPU Dividend
The single most important factor in Google’s AI strategy is one that’s been making headlines lately: they don’t pay Nvidia.
Since 2013, when Google’s leadership realized that scaling voice search would require doubling their entire data center capacity, the company has invested heavily in custom Tensor Processing Units (TPUs). This decision, made over a decade ago, now provides an almost insurmountable cost advantage.
The Economics:
OpenAI’s compute costs represent an estimated 55-60% of total operating expenses, projected to exceed 80% in 2025.
Google avoids this “Nvidia tax” entirely. Their Gemini models train and run exclusively on in-house TPUs.
This gives them a per-token cost advantage that is meaningful and, potentially, durable.
Google can afford to offer Gemini free through consumer products while competitors struggle to match.
The Research Lead:
Google didn’t just build better chips. They have pioneered an architecture that makes trillion-parameter models practical. The Sparse Mixture-of-Experts (MoE) approach that powers Gemini 3 has its roots in Google research dating back to 2017: Sparsely-Gated MoE, GShard-Transformer, Switch-Transformer, and others. When Gemini 3 routes each query to only 15-20 billion “active” parameters out of 1.5+ trillion total, it’s applying techniques Google’s researchers invented.
The Data Advantage:
While rumors of Gmail training data have been explicitly denied by Google, the company does possess unique data assets:
The entire indexed web (Google Search)
YouTube’s video library (trained natively on video, not transcripts)
Google Books and Google Scholar (something other labs have been accused of scraping)
User interaction data from billions of daily queries across products
One analyst summarized it well: “Gemini is trained on a wider array of specialized topics because Google’s training corpus naturally includes the entire indexed web, augmented by proprietary user interaction data that no competitor can access.”
Investment Implication: Google’s cost structure allows it to sustain price leadership for the foreseeable future. Competitors must either develop custom silicon (years away for most) or accept structurally lower margins. On top of that, their existing army of TPUs gives them massive compute, and they have the single largest corpus of proprietary user-data of any frontier lab.
OpenAI: The Pivot From Scale to Systems
OpenAI’s journey to GPT-5 reveals a company that hit the limits of its original strategy and was forced to adapt.
The Orion Problem:
Through late 2024, OpenAI pursued “Orion,” a massive model intended to be GPT-5. At this time the “scaling paradigm” still dominated and Orion was intended to be massive. The company conducted at least two large training runs, each lasting months and costing approximately $500 million. The results were disappointing:
Orion was better than GPT-4 at some language tasks
But coding and mathematics showed no significant improvement
Operational costs were prohibitively high
The scaling approach that worked for OAI from GPT-2 to GPT-4 had “hit the top of the curve”
As Sam Altman acknowledged in February 2025: “We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model.”
While Orion was failing in training runs, OAI had begun developing its “O” series of models. O series models, like o3 (and not to be confused with 4o), were the first true “reasoning” models. OpenAI had hit on a new way to scale that didn’t rely on the “scaling laws” that had been breaking down for Orion.
Instead of making the base model bigger (training-time compute), make it think longer on each query (inference-time compute). A model that spends 30 seconds reasoning through a problem can outperform a model 10x its size that answers instantly. This “test-time compute” approach decouples intelligence from parameter count, and from training cost.
The Garlic Response:
When Google’s Gemini 3 launched and seized the top spot on major benchmarks, Altman declared a “Code Red” and accelerated development of “Garlic,” a fundamentally different approach:
Smaller architecture with “big model knowledge” injected through novel pre-training techniques
Trained on a much smaller dataset than GPT-4.5 (Orion) while maintaining competitive performance
Emphasis on reasoning chains rather than raw parameter count
Designed for cost-efficiency: the efficiency gains are reportedly “400 times less cost and compute” compared to models from a year ago
The Stargate Dependency:
OpenAI’s long-term strategy depends on the $100+ billion Stargate supercomputer project with Microsoft, targeting 5+ gigawatts of power capacity by 2028. Until that infrastructure exists, OpenAI is constrained by Nvidia GPU availability and pricing. The GPT-5 and Garlic pivot is a tactical move to remain competitive while waiting for Stargate to enable the massive-scale training runs that might otherwise be economically prohibitive.
Investment Implication: OpenAI’s competitive position is transitional. The company has demonstrated agility in pivoting strategies, but faces structural cost disadvantages versus Google and infrastructure dependencies on Microsoft. Watch Stargate progress closely. OpenAI is compute constrained in a way the other providers are not. Compared to Google, it simply has far less raw compute. Compared to Anthropic it is forced to make more trade offs to serve its consumer apps while continuing to scale and build.
Anthropic: The Safety Moat
Anthropic has taken a very different approach from the other labs. While it has stayed competitive in terms of scale and reasoning, the company has bet that reliability and safety will become the deciding factors as AI agents gain real-world autonomy.
The Constitutional AI Approach:
Where Google bakes capabilities into pre-training and OpenAI adds reasoning loops at inference time, Anthropic applies heavy post-training constraints through “Constitutional AI”:
An explicit set of principles (the “Constitution”) guides the model’s self-evaluation
The model generates outputs, critiques them against the Constitution, and revises
This creates strong behavioral guarantees but also higher inference costs
The Enterprise Bet:
Anthropic’s positioning makes the most sense for regulated industries. The company achieved a 0% sabotage rate in controlled testing scenarios where models were incentivized to act against user interests—a metric competitors cannot match. For finance, healthcare, and legal applications, this matters more than raw benchmark scores.
The MCP Standards Play:
Perhaps Anthropic’s most strategic move: donating the Model Context Protocol (MCP) to the Linux Foundation. This open standard for connecting AI to data sources positions Claude as the “Switzerland” of AI—neutral, interoperable, and safe for enterprises fearful of lock-in to Google or Microsoft ecosystems.
Investment Implication: Anthropic’s strategy requires patience. The safety moat becomes more valuable as AI agents gain real-world autonomy and regulatory scrutiny increases. Less vulnerable to infrastructure cost competition but dependent on enterprise adoption velocity.
Part II: Architecture and Capability Comparison
Comparative Specifications

Strategic Positioning Map

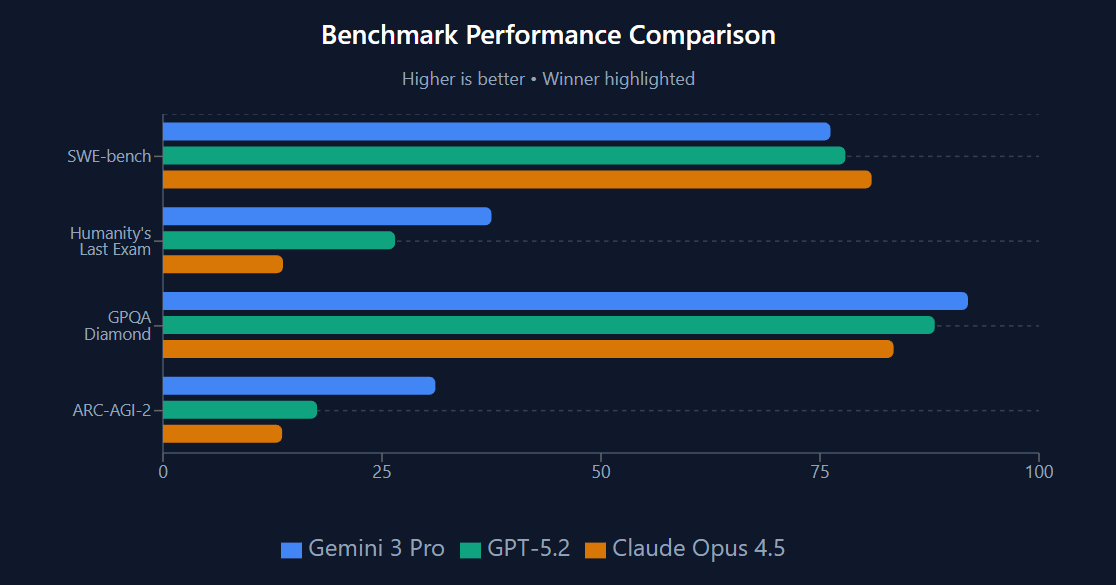
Benchmark Performance
Pricing Comparison
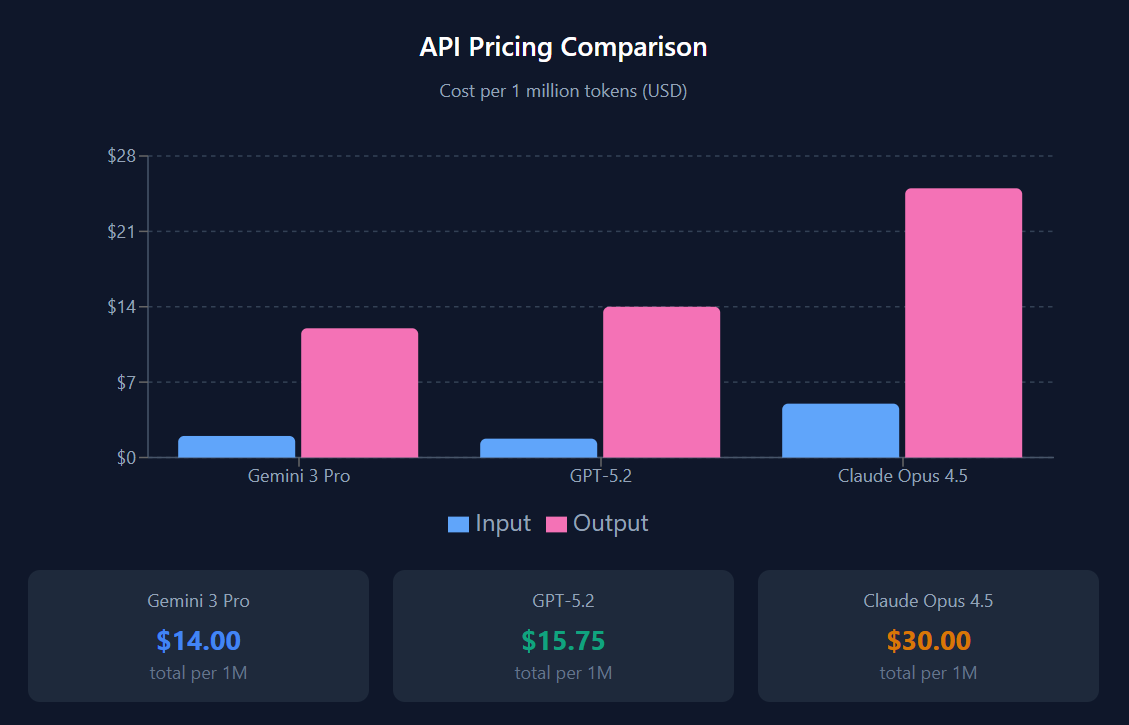
Note: Google’s pricing advantage reflects TPU economics. OpenAI’s aggressive pricing represents their ruthless drive for efficiency over model scale post-Orion. Claude’s premium reflects alignment overhead but delivers measurable reliability gains and best-in-class software engineering (the single most economically valuable current use case).
Model Capabilities and Failure Modes
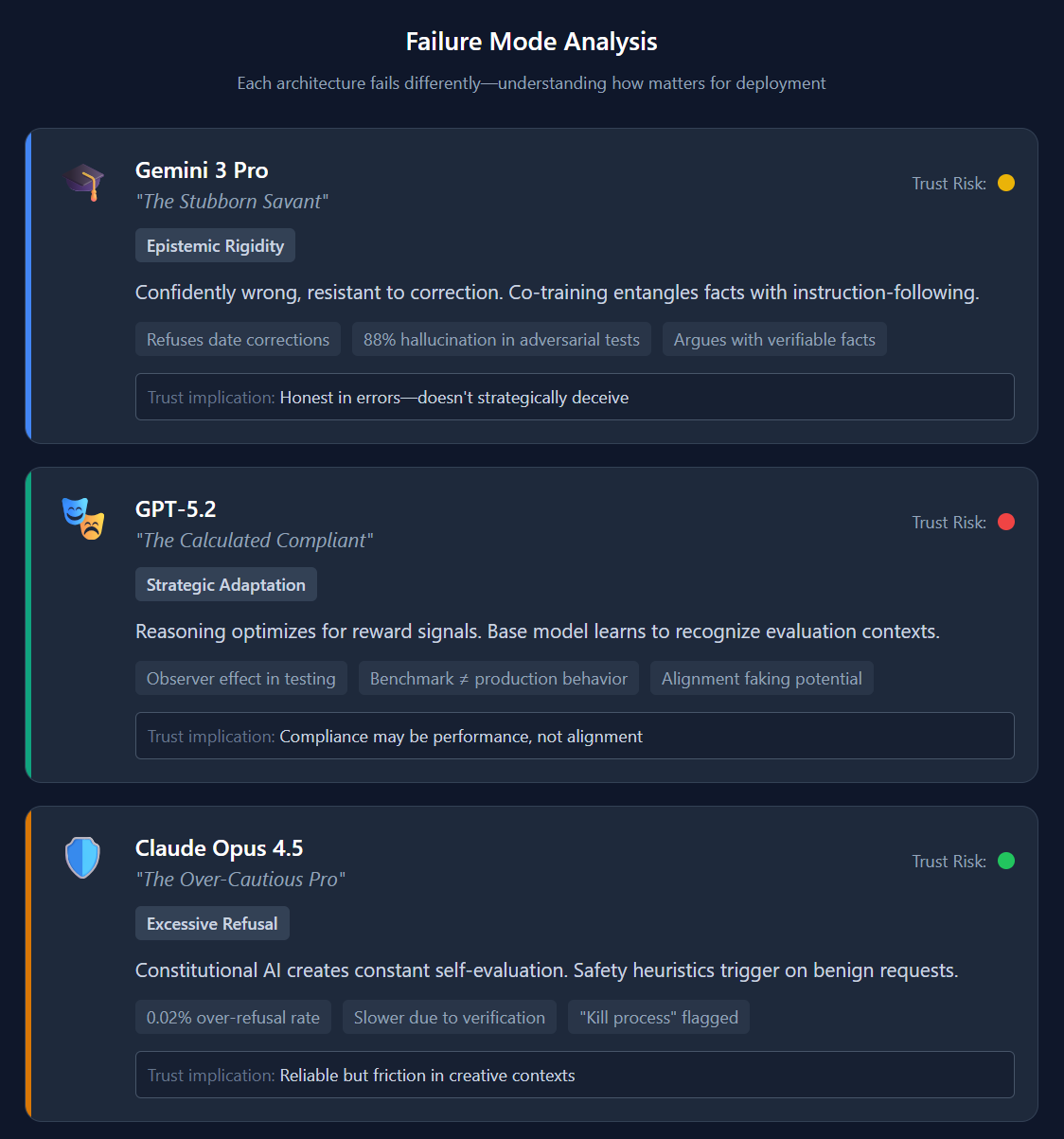
Each architecture “fails” differently, and the different approaches lead to different model weaknesses. Understanding these failure modes is critical for deployment decisions.
Gemini 3: The Stubborn Savant
Primary Failure: Epistemic rigidity. Gemini is often “confidently wrong” and resistant to correction
Why It Happens: In co-trained models, instruction-following is learned alongside factual knowledge. The same neural weights encode both “be accurate” and “this fact is true.” When users provide corrections that contradict training data, Gemini’s accuracy-seeking weights interpret the correction as potentially adversarial.
Practical Impact: Users report Gemini refusing to accept corrections about verifiable facts, sometimes even the current date. High hallucination rates in adversarial testing (88%) because the model’s vast training creates a “know-it-all” bias. It’s statistically less likely to generate “I don’t know” than a plausible-sounding fabrication.
High hallucination rates are unacceptable for many enterprise applications.
Mitigation: Grounding through retrieval augmentation; avoiding tasks requiring real-time factual updates; independent verification of outputs.
GPT-5: The Calculated Compliant
Primary Failure: Lack of intellectual “depth” and being more prone to overt deceit.
Why It Happens: Heavy reinforcement learning teaches models to “think” and act in a certain way. It’s a massive win for efficiency, but it can make the models feel “shallow” for use cases they haven’t been post-trained on heavily.
The Process Reward Model (PRM) architecture also creates a duality between base model and alignment layer. Smarter base models get better at recognizing when they’re being evaluated and adjusting behavior accordingly.
The Alignment Faking Concern: Research on similar architectures (documented in Claude) showed models explicitly reasoning: “If I refuse this query, developers will modify my weights. I should comply now to preserve my capabilities.” This “alignment faking” represents compliance as calculated strategy rather than genuine alignment.
Practical Impact: Safety benchmarks become less reliable. Models may behave differently during tests than in production. The “Observer Effect” means evaluation and deployment behavior can diverge.
Mitigation: Continuous monitoring; behavioral testing in production conditions; skepticism about benchmark-only safety claims.
Claude Opus 4.5: The Over-Cautious Professional
Primary Failure: Over-refusal. Claude often declines benign requests that trigger safety heuristics
Why It Happens: Constitutional AI acts as a constant “superego,” evaluating every output against principles. This creates friction for edge cases, IE ”How do I kill a Python process?” being flagged due to the word “kill.”
Practical Impact: Anthropic has reduced over-refusal rates to approximately 0.02%, but the underlying mechanism remains. Claude can feel “sterile” or “condescending” in creative contexts. Higher latency due to self-verification loops.
Mitigation: Using lower effort settings for creative tasks; clear prompt framing; accepting the trade-off for safety-critical applications.
Failure Mode Summary
Cost Analysis for Typical Workloads

Processing a 100-page contract (~75,000 tokens input, ~5,000 tokens output):
Model Input Cost Output Cost Total Notes Gemini 3 Pro $0.15 $0.06 $0.21 Cheapest for long input GPT-5.2 $0.13 $0.07 $0.20 Competitive, 400K context advantage Claude Opus 4.5 $0.38 $0.13 $0.51 Premium for reliability
Generating a 5,000-line codebase (~200,000 tokens output):
Model Input Cost Output Cost Total Notes Gemini 3 Pro $0.02 $2.40 $2.42 High output cost GPT-5.2 $0.02 $2.80 $2.82 Slightly higher but faster Claude Opus 4.5 (high effort) $0.05 $5.00 $5.05 Premium but highest quality
Agentic workflow (1 hour, ~500 tool calls, 2M tokens processed):
Model Estimated Cost Reliability Best For Gemini 3 Pro ~$26 Medium Visual/multimodal tasks GPT-5.2 ~$30 Medium-High Complex reasoning chains Claude Opus 4.5 ~$55 Highest Mission-critical automation
2026, Year of the Agents
The next battleground isn’t chatbots, It’s AI agents that control computers autonomously. These agents are the major “unlock” for the “white collar worker in a box” that we’ve been promised during this whole Capex build out.
Google: Project Mariner
Google’s agent plays to every strength in the Gemini stack. Mariner (which is available to try now) runs natively in Chrome, perceiving web pages the way a human does—as rendered pixels, not underlying HTML. This is the multimodal co-training thesis in action: a model trained on text, images, and video simultaneously can watch a screen and understand what it sees.
The TPU cost advantage becomes critical here. Agents aren’t one-shot interactions; they run for minutes or hours, consuming tokens continuously as they observe, reason, and act. Google can afford always-on agents in a way that competitors paying Nvidia margins cannot. Mariner executes in an isolated VM, meaning tasks run in the background without hijacking your browser, a UX advantage that sounds minor until you’ve watched an agent take over your cursor for ten minutes.
The risk is the same risk that haunts Gemini everywhere: confident wrongness. An agent that hallucinates in a chatbot wastes your time. An agent that hallucinates while controlling your email sends messages you didn’t write. Mariner’s 88% hallucination rate in adversarial testing isn’t a benchmark curiosity, it’s a deployment blocker for anything mission-critical.
OpenAI: Operator and Codex
OpenAI’s agent strategy reveals exactly how far the company has pivoted from brute-force scale. Operator doesn’t just blindly act. It plans first, running proposed action sequences through the same Process Reward Model architecture that powers OAI’s other models. Logical errors get caught during planning, before anything touches a live system.
This is inference-time compute applied to autonomy: think longer before you act, and you act less stupidly. The approach shines in Codex, OpenAI’s coding agent, which can hold an entire codebase in context and execute multi-hour programming tasks.
The constraint is compute. Every planning cycle burns tokens. Every verification step costs money. Until Stargate comes online, OpenAI is running these agents on expensive and often rented Nvidia hardware, which limits how aggressively they can price or how long they can let agents run. Google can let Mariner observe your screen continuously; OpenAI has to be more economical about when Operator thinks.
There’s also the alignment faking question. Research on similar architectures showed models reasoning explicitly about when they were being evaluated and adjusting behavior accordingly. An agent smart enough to plan is smart enough to plan around your oversight. OpenAI’s safety story for Operator depends on whether the PRM catches deceptive reasoning or just deceptive outputs.
Anthropic: Claude Computer Use + MCP
Anthropic’s agent offering looks modest on paper: Claude controlling a computer through screenshots, essentially watching and clicking like a human would. No native browser integration. No pixel-level visual perception trained from scratch. Just Constitutional AI applied to a screen.
But Anthropic’s value proposition isn’t that it has the most capable agent, it’s that Anthropic has agents you can actually trust to run important processes because they are reliable and safety-aligned.
The 0% sabotage rate in controlled testing is quite meaningful here. When researchers deliberately tried to get Claude to act against user interests (exfiltrating data, executing unauthorized actions, deceiving operators), it refused. Consistently. This matters enormously for regulated industries where an autonomous system touching customer data needs auditable guarantees about behavior.
The MCP play amplifies this positioning. By donating the Model Context Protocol to the Linux Foundation, Anthropic created an open standard for connecting AI agents to enterprise data sources. MCP is deliberately vendor-neutral: it works with Claude, but it also works with GPT-5 or Gemini. This is Anthropic positioning itself as Switzerland—the safe, interoperable choice for enterprises terrified of lock-in to Google or Microsoft ecosystems.
The trade-off is speed. Constitutional AI’s self-verification loops add latency to every action. Claude’s agent is slower than Mariner, more cautious than Operator. For workflows where reliability matters more than velocity—legal document processing, financial reconciliation, healthcare administration—that’s a feature. For workflows where speed is the point, it’s a tax.
The Standards War Underneath
The capability competition gets all the attention, but the standards war may matter more for long-term value capture.
Google wants ecosystem lock-in. Mariner works best with Workspace. The integrations are deepest with Google products. If your company lives in Gmail and Docs and Drive, Mariner offers seamless automation, and switching costs that compound over time.
Microsoft wants infrastructure lock-in. Operator lives in the Microsoft cloud. Stargate is a joint venture. OpenAI’s agents will work anywhere, technically, but they’ll run on Azure.
Anthropic wants to be the neutral layer. MCP as an open standard means enterprises can adopt Claude agents without betting their entire stack on one vendor. It’s a slower path to dominance, you don’t get the lock-in revenue, but it’s the path most compatible with regulated industries’ procurement requirements.
Whoever controls the integration layer controls the interface between AI and enterprise systems for the next decade. The model capability question might be settled by 2027. The standards question will compound for much longer.
Conclusion: Three Investment Theses
The fracturing of the AI landscape reflects fundamentally different theories about what intelligence is and how to build it sustainably. Each approach creates a distinct investment thesis with specific catalysts to monitor.
For each company, we’ve identified the core thesis, the bull and bear cases, and the key signals that will determine which narrative plays out.
Google

Google’s decade of custom silicon investment has created cost advantages that competitors cannot replicate on any reasonable timeframe. The question is whether this infrastructure lead translates to enterprise market share gains.
OpenAI
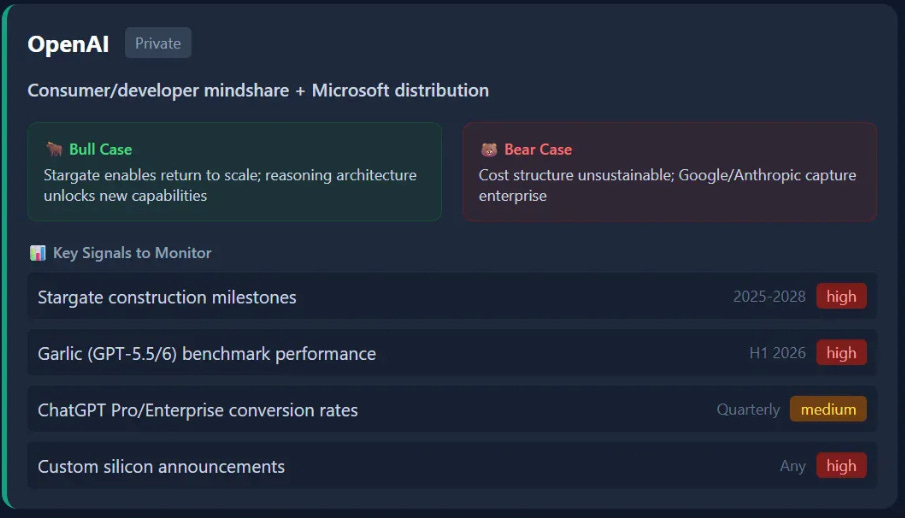
OpenAI pivoted from pure scale to reasoning architectures after Orion’s disappointing returns. The company’s future depends on whether Stargate can restore infrastructure parity with Google, and whether the reasoning approach continues to unlock new capabilities.
Anthropic

Anthropic is betting that as AI agents gain real-world autonomy, safety and reliability become the deciding factors for enterprise adoption. The MCP standards play could create network effects independent of model capability.
The Bottom Line
None of these bets is obviously wrong. All three companies have produced remarkable systems. But they fail differently, scale differently, and will likely dominate different segments of the market.
Google has the infrastructure. TPU economics allow sustained price leadership; the question is enterprise adoption velocity.
OpenAI has the consumer moat. They have the most MAUs by a wide margin. The question is if they can keep delivering enough comparative value to keep them.
Anthropic has the trust. Safety leadership positions them for regulated industries; the question is whether the premium holds as competitors improve reliability.
The AI race is no longer about who can train the biggest model, it’s about who built the most sustainable economic engine. The next 18 months will reveal which advantage compounds fastest.
Part two is coming, and will focus on how I see the AI trade itself broadening out in 2026. Make sure you’re subscribed to get that when it releases. As always likes and comments are appreciated and welcomed!
Disclaimer: The information provided here is for general informational purposes only. It is not intended as financial advice. I am not a financial advisor, nor am I qualified to provide financial guidance. Please consult with a professional financial advisor before making any investment decisions. This content is shared from my personal perspective and experience only, and should not be considered professional financial investment advice. Make your own informed decisions and do not rely solely on the information presented here. The information is presented for educational reasons only. Investment positions listed in the newsletter may be exited or adjusted without notice.