
Suddenly Everyone is a "TPU" Expert
Find out what you need to know to cut through the noise and the buzz

The Silicon Schism
Why Google’s TPUs Aren’t Eating Nvidia’s Lunch (Yet)
“Google has custom chips. They’re faster and cheaper.
Nvidia is cooked. Sell your GPUs, buy the future.”
This is the narrative making its way around twitter lately. I thought it would peter out in the aftermath of the Gemini 3 release but it hasn’t, so I want to write this post to help people navigate it.
We’ve known all along that Google was training Gemini fully on TPUs, so you can safely write off anyone acting like this is news.
What’s really happening is subtler and much more interesting.
We’re not watching a simple winner‑take‑all fight. We’re watching the AI compute market fragment.
On one side you have Nvidia, which has become the global utility for AI. Anyone with a model and a credit card can plug into CUDA and get work done. On the other you have Google, which has quietly built a hyper‑efficient walled garden using TPUs and a bespoke optical network, mostly to run its own workloads and those of a short list of VIPs.
Let’s walk through what that actually means, without getting lost in TFLOPs soup.
Two Different Games, Not One Cage Match
Start with the simplest possible description.
Nvidia’s data‑center chips are extremely flexible calculators. They can do graphics, simulations, language models, image models, “agentic” workflows with lots of branching logic, and whatever weird architecture a researcher dreams up next week. The software world has grown around that: PyTorch, TensorFlow, JAX, half of GitHub — everything assumes “this runs on Nvidia” by default.
Google’s TPUs are more like a custom engine bolted into Google’s own factory. They are purpose‑built to do one family of things incredibly well: train and serve giant neural networks, rank ads, and handle the kind of heavy inference that powers Search, YouTube, Maps and Gemini. They live inside data centers wired with Google’s own optical switching fabric, which lets them connect tens of thousands of chips into a single logical supercomputer and keep it running even as pieces fail.
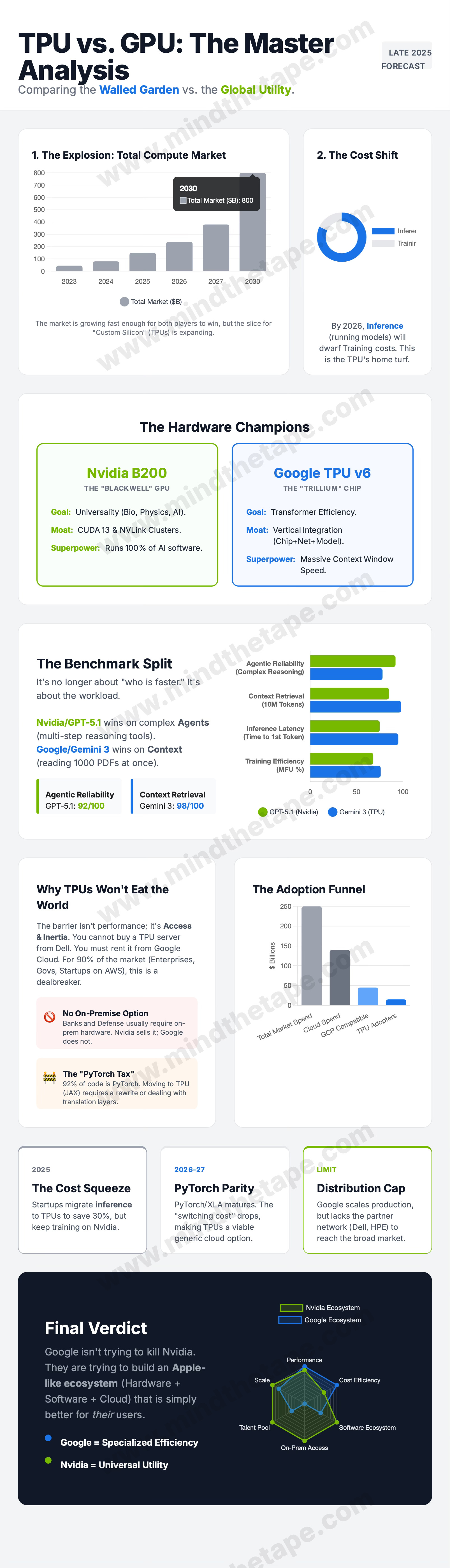
If you look at the “Hardware Champions” and “Benchmark Split” panels in the infographic, that’s what they’re really saying. Blackwell (Nvidia’s latest GPU) is the Swiss Army knife. Trillium and Ironwood (Google’s new TPUs) are scalpels. Both are sharp. They’re just designed for different jobs.
The mistake Twitter keeps making is treating scalpels and Swiss Army knives as if they’re in the same TAM.
Inside the Google Island
If we stay in Google’s world only, the TPU story is honestly fantastic.
Trillium, the sixth‑gen TPU, is advertised as roughly 4–5x more peak compute per chip than v5e, with double the memory bandwidth and about 67% better energy efficiency.
On the pricing side, Google’s own public card tells you a lot. TPU v5e starts around $1.20 per chip‑hour, Trillium around $2.70, with big discounts if you sign one‑ or three‑year commitments.
Now look at what Google is actually doing with that hardware.
Gemini — the whole family, from Ultra to the long‑context variants — is trained and served on TPU pods. Internally, the same hardware is chewing through search queries, ad auctions, YouTube recommendations and all the “AI inside Gmail/Docs/Drive” features they keep sprinkling on top of the consumer stack. When Anthropic signs a multi‑billion dollar deal for up to one million TPUs and “well over a gigawatt” of capacity, it’s plugging straight into that same infrastructure.
Seen from that angle, the “Cost Shift” and “Cost Squeeze” boxes in the infographic are the entire ballgame. Training is expensive, but it’s a mostly one‑off event. Inference is rent. It happens billions of times a day. If Google can run those tokens on home‑cooked silicon instead of paying Nvidia a 70‑ish percent gross margin on every GPU box, the savings compound into billions over the life of Gemini and everything that comes after.
So yes: within the island, TPUs are absolutely “eating lunch.” It’s just mostly Google’s own lunch.
Why the Island Has Walls
Where the internet narrative runs off the rails is when it jumps straight from “TPUs are very good inside Google” to “Nvidia is finished outside it.”
That’s where the “Why TPUs Won’t Eat the World” and “Distribution Cap” panels in the infographic come in.
First, distribution. You cannot call up Dell or HPE and order a neat little 8‑TPU box for your bank data center. TPUs come from one place: Google Cloud. If you’re a defense contractor, a regulated bank, a sovereign that wants air‑gapped hardware, or just an enterprise already pot‑committed to AWS or Azure, that alone is a deal breaker. Nvidia, by contrast, sells through every OEM and cloud you’ve heard of; it’s the default choice wherever the hardware actually lives in your racks.
Second, software gravity. Most of the world’s production models live in PyTorch and assume CUDA under the hood. Migrating a mature stack to JAX/XLA or some new TPU‑specific path is not a weekend refactor, it’s a multi‑year project. Google is trying to hide that with tools like vLLM on TPU — “give us a standard model, we’ll deploy it on whatever chips make sense” — but on the ground the friction is still real, especially outside the FAANG/AI‑lab bubble.
Third, supply. Even if everyone wanted TPUs tomorrow, Google couldn’t ship them. The limiting factor for all these accelerators is not raw silicon, it’s advanced packaging and HBM. Nvidia has locked up a huge chunk of CoWoS (Chip-on-Wafer-on-Substrate) capacity into 2026; Google, AWS and others are fighting for the rest. Packaging is slowly scaling up, but in the near term there simply isn’t enough to flood the merchant market with cheap TPUs.
That’s the physical reality behind your “Distribution Cap” box: the island is big and growing, but there are hard walls around it. You get in through Google, and Google’s first obligation is to feed its own products plus a short list of strategic partners.
What Actually Changed After Gemini
So if Nvidia isn’t getting its face ripped off, what did change when Gemini and the newer TPUs showed up?
The first thing that changed is credibility. There was a time when TPUs were still in the “interesting experiment” bucket for anyone who wasn’t Google. That era is over. Gemini is a real product; it’s competitive with every other frontier model in the wild, and it runs on TPUs front‑to‑back. When Anthropic signs for a million chips and talks about tens of billions in spend, it’s a strong external validation that this isn’t just Google dogfooding its own silicon.
The second thing that changed is how top‑tier labs think about risk. The shortage of Nvidia GPUs over the last two years forced everyone at the frontier — Google, OpenAI, Anthropic, xAI, Meta — into a multi‑vendor mindset. It’s no longer “Team Nvidia vs Team TPU,” it’s “How do I get as many useful flops as possible, from as many credible vendors as possible, without blowing up my training stack.” Nvidia is still the anchor, but TPUs, Trainium and various in‑house chips now matter at the margin.
The third shift is Google’s own ambition. Early on, TPUs looked like a margin‑preservation tool: a way to internalize the “Nvidia tax” on Search and YouTube. The newer moves — public Trillium pricing, vLLM on TPU, Ironwood marketing aimed at inference economics — say something different. Google wants a real share of the cloud AI compute market, not just a cost hedge.
That’s what your “Adoption Funnel” in the infographic is hinting at: start with deep internal workloads, then pull in trusted labs like Anthropic, then gradually hand more of that toolchain to the broader cloud customer base once the software is boring and robust enough.
What Hasn’t Changed: Nvidia’s Mainland
Against that backdrop, Nvidia’s position looks less like “end of days” and more like “sharing the top of the food chain with new species.”
Nvidia still owns the part of the market that looks like the mainland: enterprises, sovereigns, small and mid‑sized AI shops, anyone who wants hardware they can put where they want, run whatever frameworks they want on, and swap between clouds with minimal drama.
CUDA is still the default. PyTorch is still the dominant framework. Every tool, library and MLOps platform in the wild assumes “there will be Nvidia GPUs under this somewhere.” That inertia is not going away in the next year or two just because TPUs have better efficiency on a subset of workloads.
The “Final Verdict” radar chart in your infographic is pretty much my entire view in one picture. Google scores higher on cost efficiency and sheer scale inside its own walls. Nvidia scores higher on flexibility, software ecosystem, and distribution everywhere else. Both win their home games. Neither is about to starve.
What to watch — signals that Google is moving from “island” to “threat”:
External TPU deployments accelerating: Google just signed a deal to deploy TPUs in a third-party data center (Floydstack in NYC) for the first time . If this becomes a pattern — TPUs in non-Google racks — the walled garden narrative could start to break down.
Developer activity on TPU/JAX rising: DA Davidson noted TPU developer activity increased ~96% in the past six months . Watch whether this continues.If JAX/XLA starts eating into PyTorch/CUDA mindshare, the software moat erodes.
Ironwood adoption outside Google: Ironwood is inference-optimized and competitive with Blackwell on paper (4.6 PFLOPs FP8, 192GB HBM) . If major inference workloads start migrating to Ironwood via Google Cloud, that’s real revenue at risk for Nvidia.
More Anthropic-style deals: Anthropic committed to 1M TPUs while still using AWS Trainium and Nvidia GPUs . If other frontier labs follow a multi-vendor strategy that includes TPUs, Nvidia loses pricing power.
Packaging capacity shifts: If Google or TSMC announcements suggest CoWoS/HBM capacity is being reallocated toward TPU production, that’s a supply-side signal that Google is scaling external ambitions.
How I’d Frame It as an Investor
TPUs are not sprinting across the field to tackle Nvidia. They’re quietly rearranging which parts of future compute spend are even available to Nvidia in the first place.
And while I have spent a lot of this post minimizing the “TPUs are coming for NVDA” takes, this is a real threat.
Every TPU that runs a Gemini query, every Trainium that runs an AWS model, every in‑house chip Meta deploys in its recommendation stack — those are dollars that never even show up in Nvidia’s addressable market. The top of the capex stack is becoming a split economy: custom silicon for hyperscalers’ own workloads, Nvidia for everything they sell on to the rest of us.
However it’s important to remember a few key things:
It’s not trivial for other hyperscalers to go out and replicate Google’s success! They’ve been doing this for 10 years. It’s an open question whether the other hyperscalers could get the same results.
Google building out an ecosystem that is competitive with NVDA is a long way off at best.
The questions I care about from here are less “TPU or GPU, who wins?” and more:
How fast does Google manage to make TPUs boring and invisible behind standard interfaces so that the walled garden grows beyond the current VIP list?
How quickly does advanced packaging capacity expand, and who actually locks it up?
Does the AI workload mix drift toward more “agentic,” messy tasks that structurally favor flexible GPUs, or does most of the volume live in big, steady LLM inference where fixed‑function accelerators shine?
None of those have easy answers yet. But they all live downstream of the same basic picture:
Google has built an insanely efficient island.
Nvidia still powers the mainland.
Good luck out there.
If you want to win a FREE premium subscription to MindTheTape.com, just like this post. If it gets 10 likes I will give away a few subs. Liking and restacking also helps motivate me to do more of these deep dives, which are really a lot of work!
Disclaimer: The information provided here is for general informational purposes only. It is not intended as financial advice. I am not a financial advisor, nor am I qualified to provide financial guidance. Please consult with a professional financial advisor before making any investment decisions. This content is shared from my personal perspective and experience only, and should not be considered professional financial investment advice. Make your own informed decisions and do not rely solely on the information presented here. The information is presented for educational reasons only. Investment positions listed in the newsletter may be exited or adjusted without notice.
Really good analysis, thanks!